
In the highly competitive world of Software as a Service (SaaS), availability isn’t a feature—it is the bedrock of your business model. Modern users expect applications to work flawlessly, 24/7, regardless of whether your team is shipping a minor patch or a massive new feature.
This guide explores the engineering discipline required to achieve Zero-Downtime Deployment for SaaS, moving beyond basic DevOps theory to focus squarely on the business impact: Ensuring seamless user experience and reliability while unlocking continuous innovation.
Launch Your App Today
Ready to launch? Skip the tech stress. Describe, Build, Launch in three simple steps.
BuildAs we dissect the complexities of sophisticated deployment, we will show how platforms like Imagine.bo are leveling the playing field, making enterprise-grade reliability accessible to every SaaS founder and product leader without requiring a massive, specialized DevOps team.
The Business Imperative: Why Seamless Deployments Define Modern SaaS Success

Zero-Downtime Deployment (ZDD) is the seamless process of migrating or updating your system without interruptions, ensuring services remain accessible and functional throughout the transition. This capability is no longer optional; it is a critical differentiator.
The True Cost of Downtime
The financial implications of service interruption are staggering. Unplanned application downtime averages between $1.25 billion to $2.5 billion annually for Fortune 1000 companies. For large enterprises, unplanned downtime can cost up to $23,750 per minute.
Beyond direct revenue loss—such as abandoned transactions on an e-commerce site or productivity losses for businesses reliant on a critical SaaS platform—downtime erodes the two most valuable assets: trust and reputation. When your systems stay live while competitors struggle, you gain a massive competitive advantage.
Business Impact of ZDD
- Revenue Protection: Continuous service ensures transactions and conversions proceed uninterrupted, preventing lost sales and minimizing financial penalties associated with missed Service Level Agreements (SLAs).
- Enhanced User Experience: Users expect services to work all the time; ZDD eliminates frustration by making updates invisible, building loyalty and positive perception.
- Faster Innovation Cycles: The ability to roll out updates safely and frequently allows teams to iterate quickly, fix bugs promptly, and stay ahead of changing market demands using automated CI/CD for AI SaaS.
The Fundamentals of Zero-Downtime Deployment
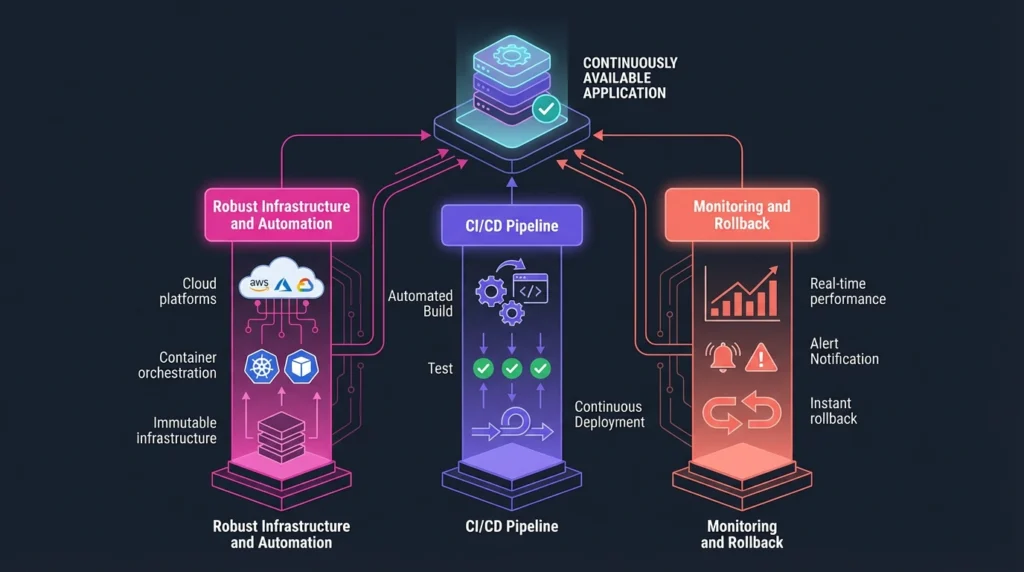
Achieving ZDD is a testament to robust DevOps processes, primarily anchored by the Continuous Integration/Continuous Deployment (CI/CD) pipeline. This workflow automates building, testing, and deployment, minimizing the risk of human error that often plagues manual processes.
1. Robust Infrastructure and Automation
ZDD requires a scalable, rock-solid foundation, typically leveraging cloud platforms (AWS, Azure, GCP) and container orchestration tools like Kubernetes. The use of Immutable Infrastructure—where a new instance is provisioned and deployed with every change instead of modifying the existing server—ensures consistency and predictability.
2. CI/CD: The Engine of Reliability
A CI/CD pipeline ensures every code change undergoes automated testing (unit, integration, end-to-end tests) to validate changes before they reach production. This automation enables quick and frequent releases with minimal downtime risk.
3. Monitoring and Rollback
If something goes wrong during deployment, you need to catch it immediately and revert changes instantly. Real-time monitoring and alerting (tracking response time, error rates, resource utilization) are critical during the rollout phase. Furthermore, rollback procedures must be in place to allow teams to revert swiftly to a previous stable version.
Core Strategies for Zero-Downtime Deployment
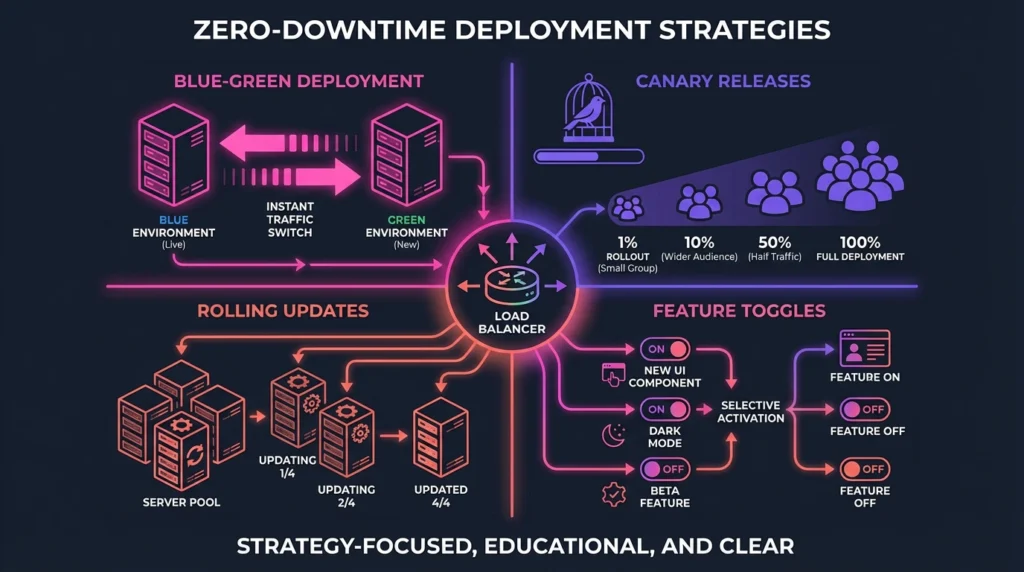
Modern SaaS architects utilize several deployment patterns to keep the application live while updates roll out in the background.
1. Blue-Green Deployment: The Instant Switch
- Mechanism: Blue-Green involves maintaining two identical production environments: Blue (currently live, serving traffic) and Green (standby, receiving the new version). The update is deployed and thoroughly tested in the Green environment. Once validated, the load balancer instantly switches all live traffic from Blue to Green.
- Business Value: This strategy minimizes risk because the old version remains operational until the switch is confirmed successful. Rollback is as simple as flipping the traffic switch back to the stable Blue environment if issues arise.
- Considerations: This method requires duplicating infrastructure resources during the deployment window, which can increase costs.
2. Canary Releases: The Gradual Rollout
- Mechanism: Canary deployment introduces updates to a small subset of users or servers (the ‘canaries’) before scaling SaaS with automation across the entire infrastructure. This subset acts as an early warning system.
- Business Value: Canary releases are crucial for risk mitigation and real-world testing. By limiting exposure initially, teams can monitor performance metrics (like error rates and latency) with a small group of users. If metrics remain healthy, the rollout expands incrementally; if problems occur, the deployment is halted or reversed before widespread impact.
- Real-World Example: Netflix is known for using advanced canary deployment practices to ensure safe, automated rollouts across their massive microservices architecture.
3. Rolling Updates: The Incremental Replacement
- Mechanism: Rolling updates incrementally replace old instances with new ones in a staggered fashion. Load balancers ensure continuous service by routing traffic only to the operational instances. For example, in a system of ten servers, only one or two might be updated at a time.
- Business Value: This approach is resource-efficient as it does not require duplicate infrastructure. It’s particularly effective for large-scale applications built on microservices, ensuring continuous availability throughout the process.
- Considerations: Rollback can be more complex than Blue-Green, as the system must revert individual components.
4. Feature Toggles (Feature Flags): Decoupling Release from Deployment
- Mechanism: Feature toggles allow developers to deploy new code and features into production environments but keep them disabled by default using runtime configuration switches.
- Business Value: This technique decouples deployment from the actual feature release. You can push a new feature to production, test it internally (dark launching), and then activate it selectively for specific user cohorts or A/B testing.
The Riskiest Step: Database Migrations
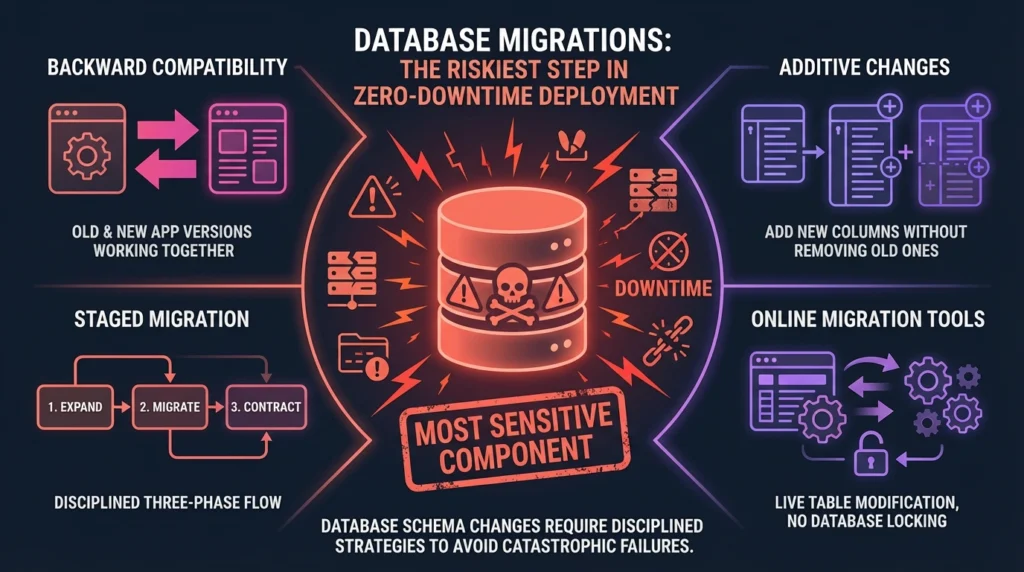
While application servers can be updated quickly and rolled back easily, database schema changes pose the biggest threat to zero-downtime goals. The database is stateful and shared, making poorly planned changes potentially catastrophic. Understanding backend development essential skills is crucial here.
To safeguard data availability, architects must adopt disciplined strategies:
- Backward Compatibility: This is paramount. Design schemas so that both the old version and the new version of your application can read and write data seamlessly during the transitional period.
- Additive Changes (Expand Phase): When updating schemas, always add new columns or tables first. Avoid destructive actions like dropping or renaming tables during deployment, as these can cause immediate application failures.
- Graceful Migration and Contract: Perform migrations in multiple stages: first deploy the backward-compatible schema change (Expand), then update the application logic to use the new schema (Migrate), and only in a subsequent release, Contract by removing the deprecated schema components.
- Online Migration Tools: Utilize tools designed for live environments (like gh-ost) that can modify large tables without locking them, significantly reducing the risk of downtime during schema changes.
The Challenges for Startups and Non-Technical Founders
Zero-Downtime Deployment, while essential, traditionally requires significant upfront investment and specialized expertise. For startups and product leaders who are not experienced DevOps engineers, the journey often involves several hurdles:
- Complexity and Steep Learning Curve: Implementing strategies like Blue-Green or Canary releases often necessitates deep knowledge of Kubernetes, load balancing tools, and complex CI/CD orchestration.
- High Infrastructure and Skill Cost: Maintaining dual, identical production environments is resource-intensive. Furthermore, hiring skilled DevOps professionals is costly.
- Legacy Debt: If the application wasn’t built with modern microservices or containerized architecture, retrofitting zero-downtime capabilities can feel like trying to upgrade a legacy system lacking support and modern functionality. This is a common challenge when trying to master AI vs no-code MVP guides for fast startup launches.
The Modern Solution: AI-Driven No-Code Deployment with Imagine.bo
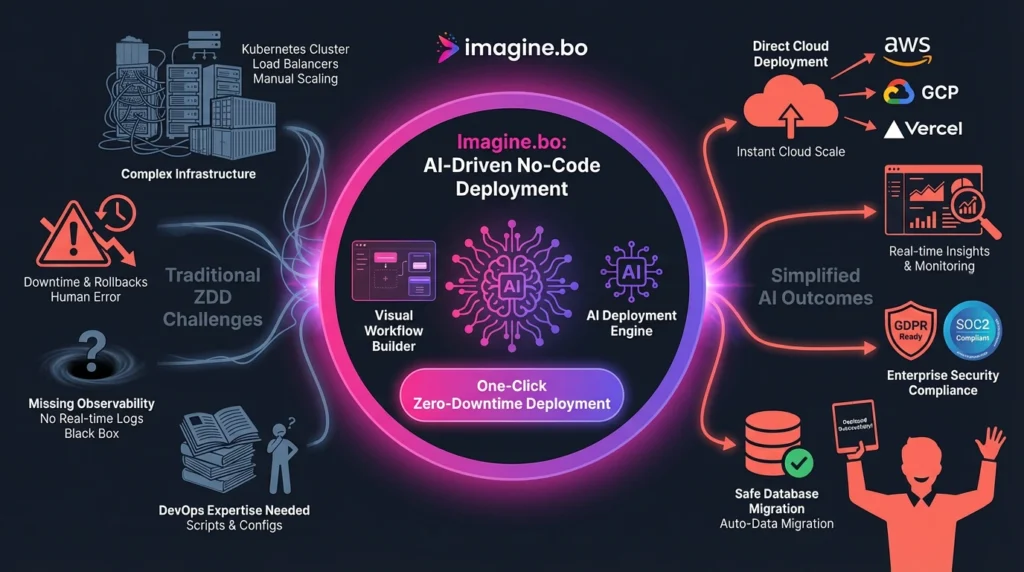
Achieving enterprise-level reliability should not be limited by engineering budget or specialized skills. This is where AI-driven platforms shift the paradigm. AI-powered no-code app development platforms like Imagine.bo are designed specifically to simplify ZDD, allowing SaaS founders and product leaders to build, customize, and deploy scalable applications without writing code.
| ZDD Challenge | How Imagine.bo Simplifies Deployment |
| Complex Infrastructure Setup | Imagine.bo offers deployment directly to major cloud providers (AWS, GCP, Vercel). The underlying AI-driven architecture handles the container orchestration and scaling, removing manual infrastructure management. |
| High Deployment Risk | By automating the deployment pipeline entirely through a visual framework, Imagine.bo drastically reduces human error. DevOps one-click deployment becomes the standard, making releases repeatable and traceable. |
| Missing Observability | Imagine.bo includes built-in analytics. This functionality provides immediate performance feedback and monitoring during rollout, fulfilling the critical need for real-time assessment. |
| Security and Compliance | The platform provides enterprise-grade security features, ensuring compliance and protection (like GDPR and SOC2) are baked in out-of-the-box. |
| Database Migration Safety | The AI-driven system can enforce best practices like backward compatibility and staged rollouts for schema changes, ensuring data consistency and safety. |
Imagine.bo moves the focus from how to deploy (DevOps complexity) to what to deploy (feature velocity), reducing risk, cost, and time-to-market.
Best Practices for Operational Excellence
Whether you use a traditional DevOps stack or a platform like Imagine.bo, maintaining zero-downtime requires adherence to fundamental operational discipline.
- Automate Testing Comprehensively: Integrate automated testing (unit, integration, and E2E) into your pipeline to validate changes early.
- Monitor Real-Time Performance: Deployments must be monitored closely for performance metrics like response time and error rates.
- Plan and Drill Rollbacks: Issues will arise. Maintain robust rollback procedures that allow instantaneous reversion to the last known stable version.
- Embrace Incremental Changes: Release smaller, more frequent updates. This lowers the “blast radius” of any potential failure.
- Clean Up Feature Flags: If you use feature toggles, regularly audit and remove obsolete or unused flags to avoid technical debt.
Conclusion: Tying Reliability to Innovation and Growth
Zero-Downtime Deployment is not merely an IT achievement; it is a fundamental business strategy for Ensuring Seamless User Experience and Reliability in the modern SaaS landscape. By implementing deployment strategies like Blue-Green, Canary Releases, Rolling Updates, and careful database migration practices, organizations ensure continuous service delivery.
For SaaS founders and product leaders focused on speed and market validation, the traditional complexity of building and maintaining a perfect deployment pipeline is often overwhelming.
Imagine.bo bypasses this heavy engineering complexity. By providing an AI-powered, no-code environment that inherently supports highly scalable SaaS architecture with AI tools, Imagine.bo delivers Zero-Downtime Deployment as a managed service. This enables non-technical teams to achieve the gold standard of operational reliability, allowing you to focus time and capital on product innovation and growth, rather than infrastructure upkeep and crisis management.
Start building a future-ready SaaS product where reliability is a guarantee, not an engineering challenge.
Launch Your App Today
Ready to launch? Skip the tech stress. Describe, Build, Launch in three simple steps.
Build




